Git Internals
This post is the second part of a series on the internal working of Git.
The Git Internals series
- The
.gitDirectory - Git Objects (This post)
The entire Git Internals series is available as a talk as well. Feel free to watch the talk instead. 👇
Git Objects
Git has two data structures, a mutable index that caches information about the working directory and the next revision to be committed, and an immutable, append-only object database (repository) containing four types of objects
- Blob Object
- Commit Object
- Tree Object
- Tag Object
Git carries out its version control using these objects to store data and the internal working of Git can be understood by understanding these objects.
Some part of the internal working of Git will be explored through an example in this section.
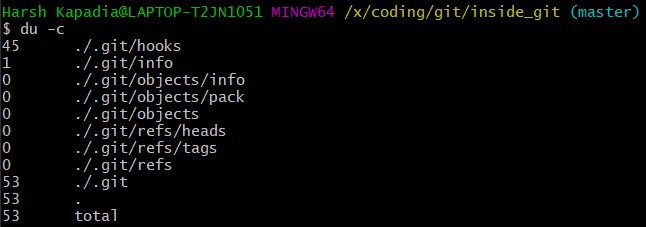
Run git init to initialize an empty repository in the inside_git directory (root directory). A hidden directory .git is created in this root folder.

The command du -c is used to list the sub-directories of inside_git and their sizes on disk (in kbs).
The blob Object
NOTE: A Blob Object stores the contents of a file.
Create a new file in the root folder.

Now the working tree (root directory) contains the .git directory and the new file master_file_1.txt.

Add the file to the staging area using git add . and run du -c once again.
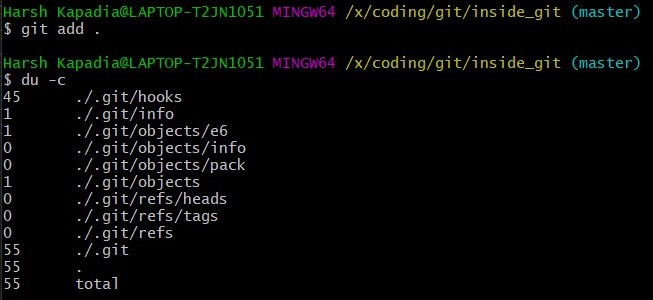
Note that a new directory e6 has been added to .git/objects.
Use the dir (or ls) command to find out which file is present in the directory .git/objects/e6.

The file name 9de29bb2d1d6434b8b29ae775ad8c2e48c5391 is 38 characters long. On appending it to the folder name (e6), it becomes a 40 character string e69de29bb2d1d6434b8b29ae775ad8c2e48c5391. This is a SHA-1 hash. Git hashes the content of the file (and some more data) using the SHA-1 algorithm to produce a 40 character hexadecimal string. Every stage, [commit] and [tag] produces its own unique SHA-1 hash(es). (Being a 40 character string, hash collisions are VERY rare.) The first two characters of the hash are used for bucketing the hashes into folders, to decrease access time. To make things easy, Git sometimes uses just 4 to 8 characters of an object’s hash to refer to it.
As mentioned in the previous paragraph, Git hashes the contents of the file and other details to create a 40 character SHA-1 hash. To verify that, some content needs to be added to the file. The file will then have to be added again. (This will produce another hash.)

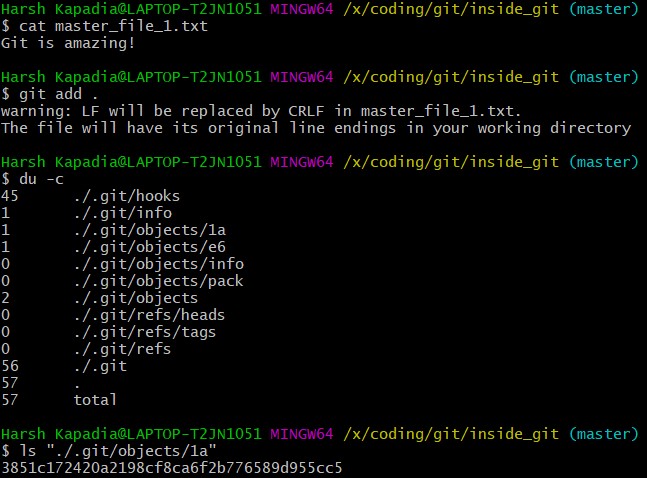
From the last command in the image above, it can be inferred that a new hash 1a3851c172420a2198cf8ca6f2b776589d955cc5 was generated. Check its contents using the cat command.

The output is gibberish because Git compresses file contents (and some additional data) with the Zlib library and then stores it in the file. So to make sense of the gibberish, the content of the file needs to be de-compressed.

blob 16\0Git is amazing!\n is the content of the hashed file. (\0 and \n are not seen. Explained in the points below.)
Breaking it down
blobis the object type of the file. It is an abbreviation for ‘Binary Large OBject’. These objects (files) store the content of the files.16is the file size (length).Git is amazing!consists of 15 characters, but theechocommand adds a new line (line feed) character (\n) at the end of the text, making the length 16.- Just like the
\ncharacter which cannot be seen in the output, there is a NULL character (\0) between the length and file content. Git is amazing!\nis the file content. (The\nis not visible.)
NOTE: If blob 16\0Git is amazing!\n is hashed using SHA-1, the same hash (1a3851c172420a2198cf8ca6f2b776589d955cc5) will be generated!
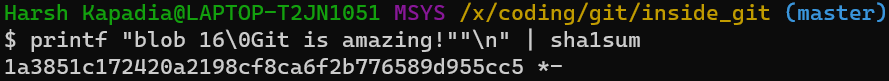
So, Git generates the hash of the file using the string <object_type> <content_length>\0<file_content> and stores that string in the file after compressing it. (The name of the file is the last 38 characters of the 40 character hash that was generated. The first two characters are used for bucketing.)
TIP: The process of finding the contents of the file using cat is pretty cumbersome. It is a better idea to use the git cat-file [plumbing command] provided by Git.
Variations of the git cat-file command that will be used
git cat-file -p <hash>(-p = pretty print) to display file data.git cat-file -t <hash>(-t = type) to display file type (blob, commit, tree or tag).git cat-file -s <hash>(-s = size) to display the file size (length).
The commit Object
NOTE: A Commit Object links Tree Objects together into a history. It contains the name of a Tree Object (of the top-level source directory), a timestamp, a log message, and the names of zero or more parent Commit Objects.
Commit master_file_1.txt and then run du -c again.
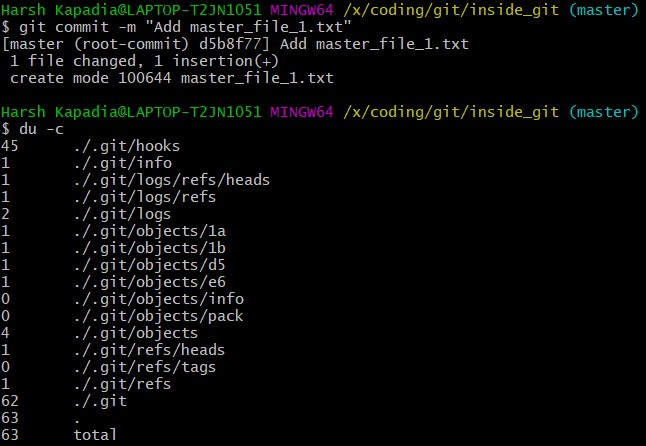
From the above image it can be noticed that two new directories .git/objects/1b and .git/objects/d5 were created. Also, after committing the file, Git printed the first seven characters of the SHA-1 hash for that commit in the output.
Using the seven characters of the commit hash in the output, check the file type using the git cat-file -t command.

So the file type is commit, inferring that it is a file generated through a commit.
Print the contents of the Commit Object (file) using the git cat-file -p command.

Commit Object content
tree 1b2190cdc2801ec3df6505dc351dee878ac7f2fcis the other SHA-1 hash that was generated (remember that two directories were generated in.git/objectson committing the file), of the typetree. The tree is the [snapshot] of the current state of the repository.- Parent commit’s SHA-1 hash (Not present here. Explained below.)
- The next line has the details of the author (the one who wrote the code):
- Name
- e-mail ID
- Timestamp
- The next line has the details of the committer (the one who committed the code):
- Name
- e-mail ID
- Timestamp
- Commit message
- Commit description (If provided. Not present here.)
The tree Object
NOTE: A Tree Object is the equivalent of a (sub)directory: it contains a list of filenames, each with some type bits and the name of a blob or Tree Object that is that file, symbolic link, or directory’s contents. This object describes a snapshot of the source tree.
Check the contents of the tree file listed in the Commit Object (file).

The tree file has entries of the files & directories in the snapshot (current state) of the local repository. The format of each line is the same.
Tree Object content format
100644is the mode of the file. It is an octal number.Octal: 10 0 644 Binary: 001000 000 110100100- The first six binary bits indicate the object type.
001000indicates a regular file. (As seen in this case.)001010indicates a symlink (symbolic link).001110indicates a gitlink.
- The next three binary bits (
000) are unused. - The last nine binary bits (
110100100) indicate Unix file permissions.644and755are valid for regular files.- Symlinks and gitlinks have the value
0in this field.
- The first six binary bits indicate the object type.
blobis the object type. (It can be atreeobject as well. Explained below.)1a3851c172420a2198cf8ca6f2b776589d955cc5is the SHA-1 hash of the file.Name of the file.
So, each Commit Object points to a Tree Object and each Tree Object points to a set of blobs and/or trees, which correspond respectively to files and subdirectories.
The connections between the commit, tree and blob files till now. (HEAD is just a pointer to the latest commit.)
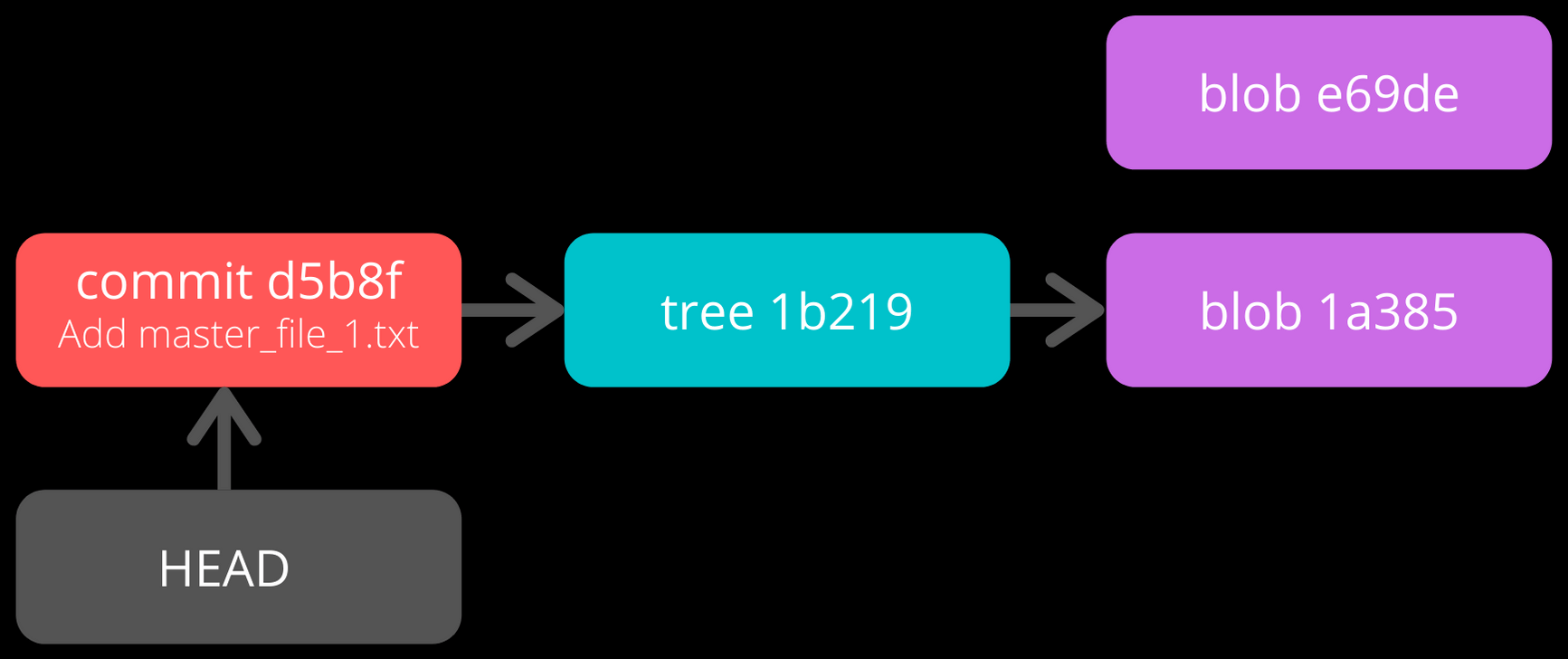
NOTE: The blob e69de has been modified to blob 1a385 and so is not connected to the tree 1b219. Only the latest blob of every added file is connected to the new Tree Object when a commit is made.
Parent Commits
Create another file (master_file_2.txt), add it and commit it.
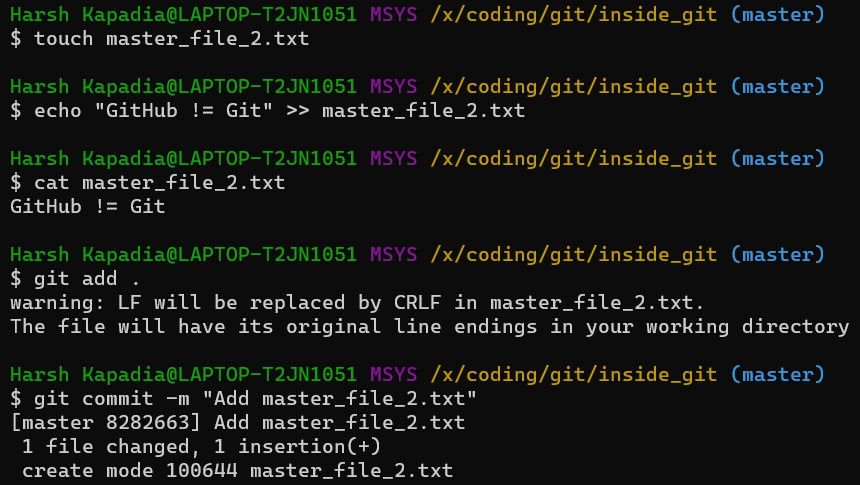
Check the contents of the commit file (using part of the hash 8282663 as seen in the above image).
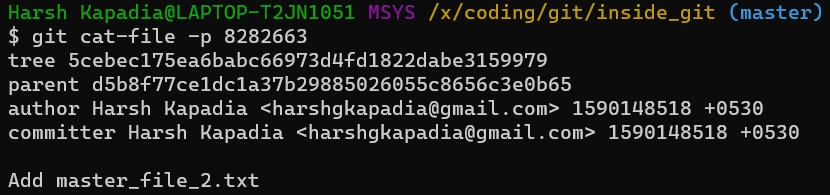
A new line parent d5b8f77ce1dc1a37b29885026055c8656c3e0b65 is seen. Remember, this is the hash of the previous commit. Git is thus creating a graph. A Directed Acyclic Graph to be precise. (Check image below.)
Also, the HEAD will now automatically point to this (latest - 82826) commit rather than the parent (previous - d5b8f) commit as it was doing before. To verify, check where the HEAD is pointing.

It is pointing to the latest commit (82826).
Now check the contents of the Tree Object of the latest commit.

From the Commit Object, Tree Object and HEAD position, the connection graph looks as follows
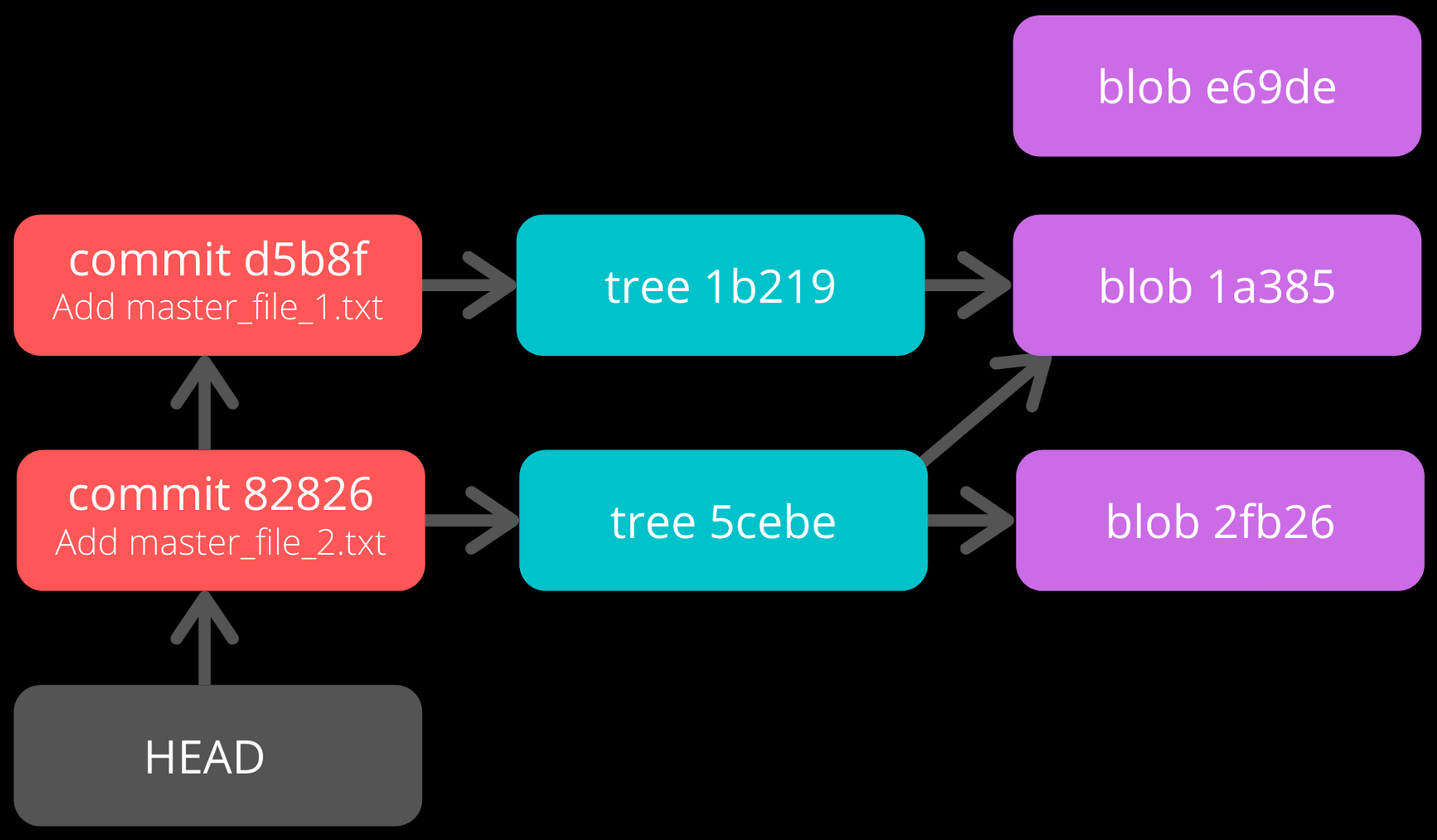
Creating Directories
Create a new file (master_dir_1_file_3.txt) inside a directory (dir_1), add it, commit it and look at the contents of the commit file.
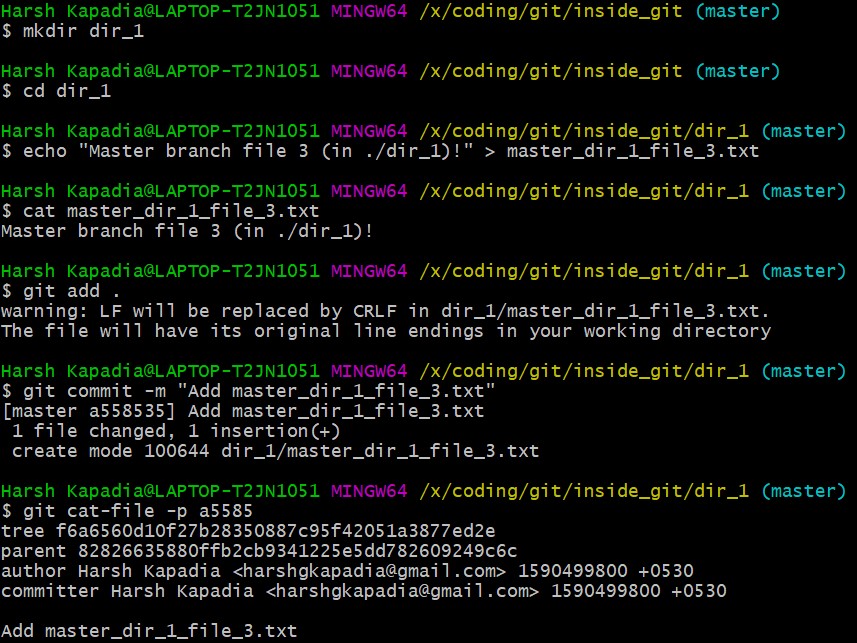
The commit file has the same format as before.
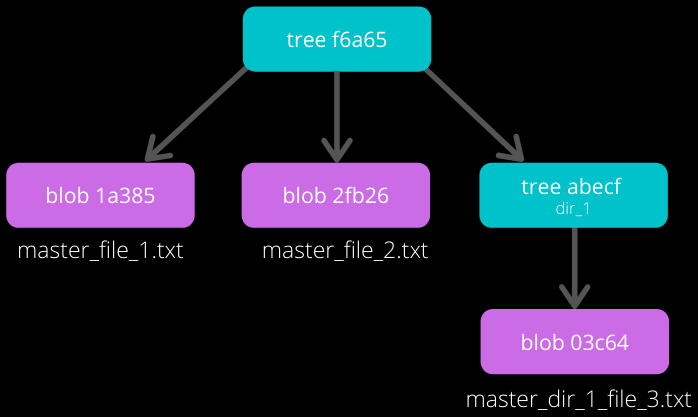
Check the contents of the tree file (with the hash f6a65 as seen in the above image).

It is surprising to note that the tree f6a65 points to another tree abecf! The name of the new tree is dir_1.
Check the contents of the dir_1 tree.

So it points to the file (master_dir_1_file_3.txt) inside the directory dir_1.
Have a look at how the tree f6a65 connected itself to the tree and blobs.
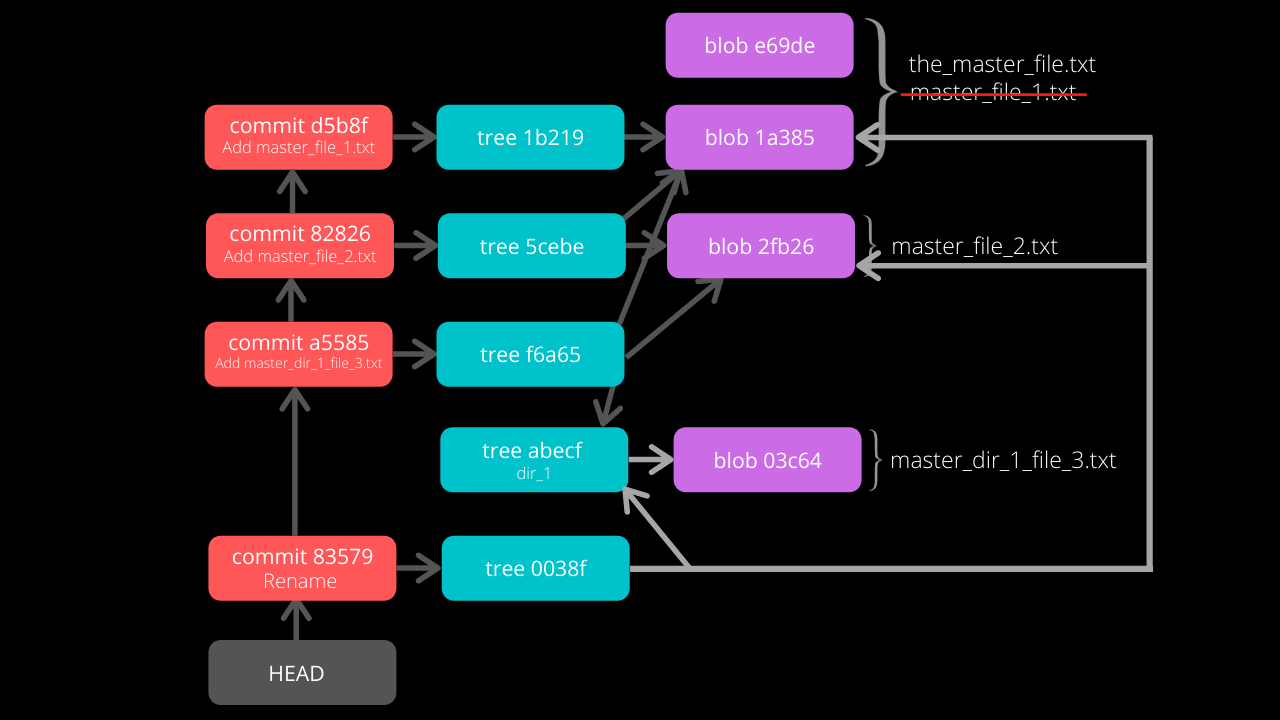
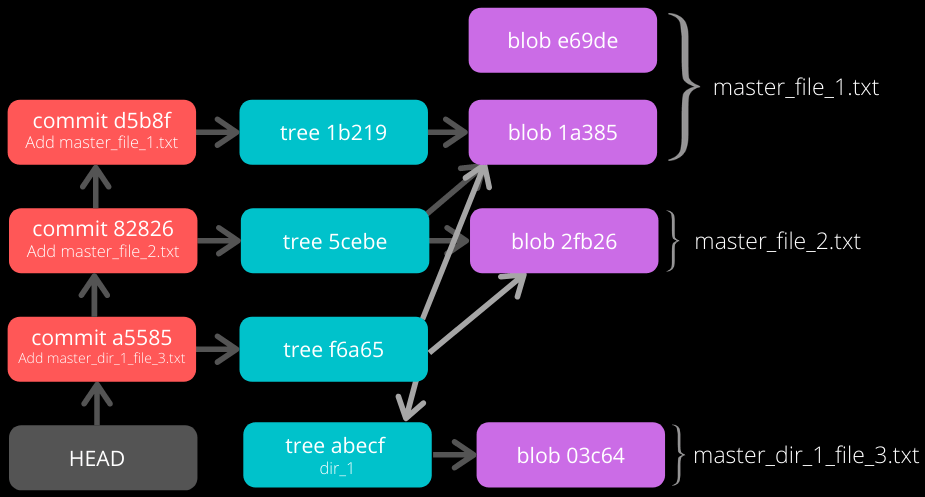
The graph of the repository as it stands now
Renaming Files
Rename master_file_1.txt to the_master_file.txt to see how Git handles it internally.

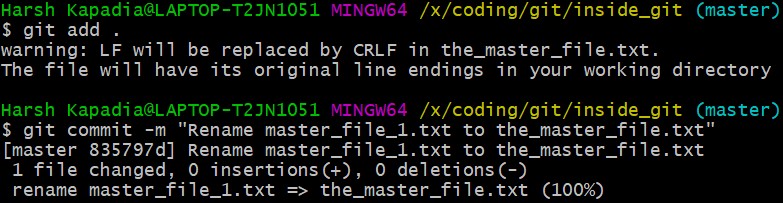
When the file is committed, Git is smart enough to recognize that a file was renamed and is not a new file, as can be seen in the last line of the above image. It can recognize this because the SHA-1 hash of the file has not changed (as the content of the file has not changed).
Check the contents of the commit and tree files.

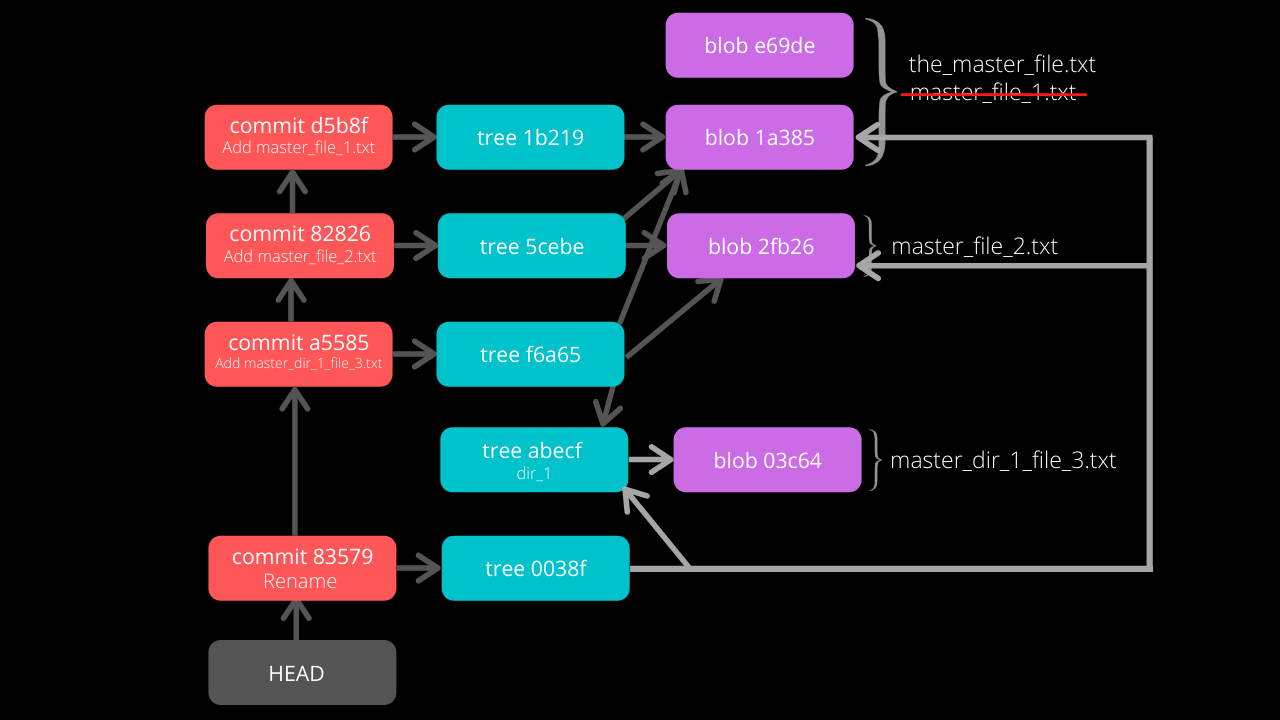
From the last line, the hash 1a385 is same as the hash of the original file name (master_file_1.txt) and just the name of the file has been changed in the Tree Object instead of creating a new blob file. This is efficient space management by Git!
The structure of the repo.
Modifying Large Files
Add and commit a image to Git. The size of the image is 1.374 Mb (or 1374 kb), so it is a relatively huge file as compared to the other files (~ 1 kb/file).
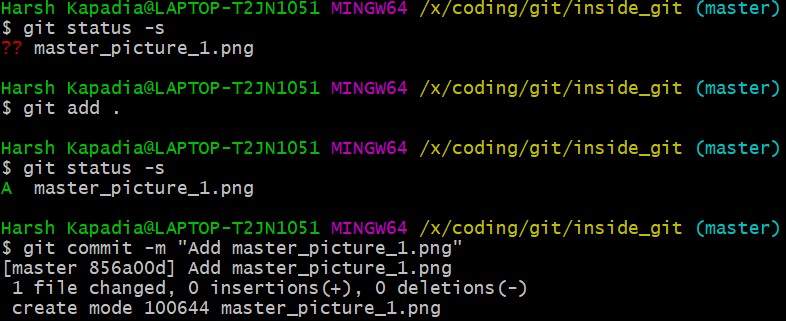

Make a small change to the image file contents and then add and commit it again.
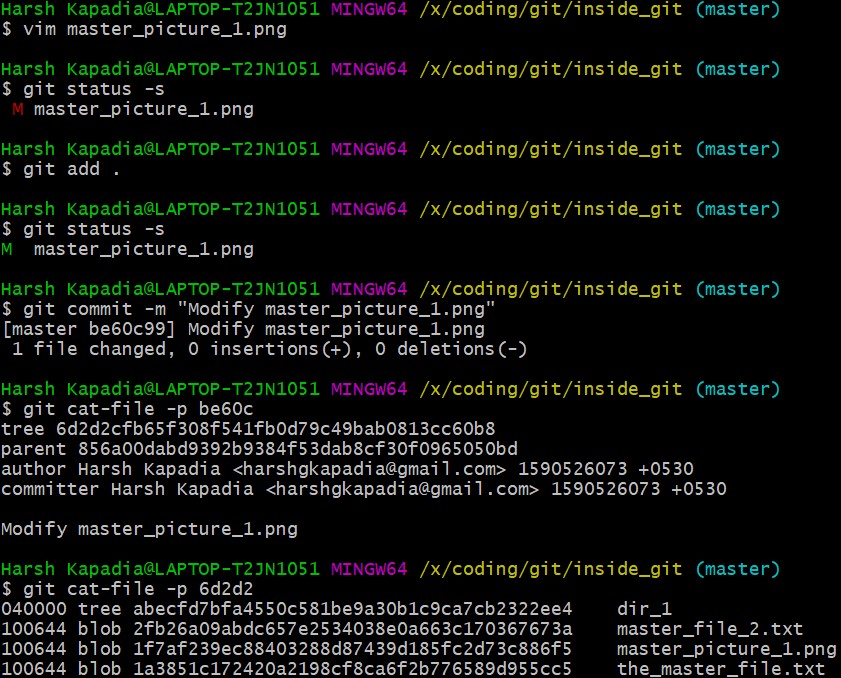
The SHA-1 hashes of master_image_1.png in the latest (6d2d2) and previous (27666) tree are different, so Git has created two different blobs (ca893 and 1f7af) for the same file, even when they only have a very small difference.
Run du -c now.
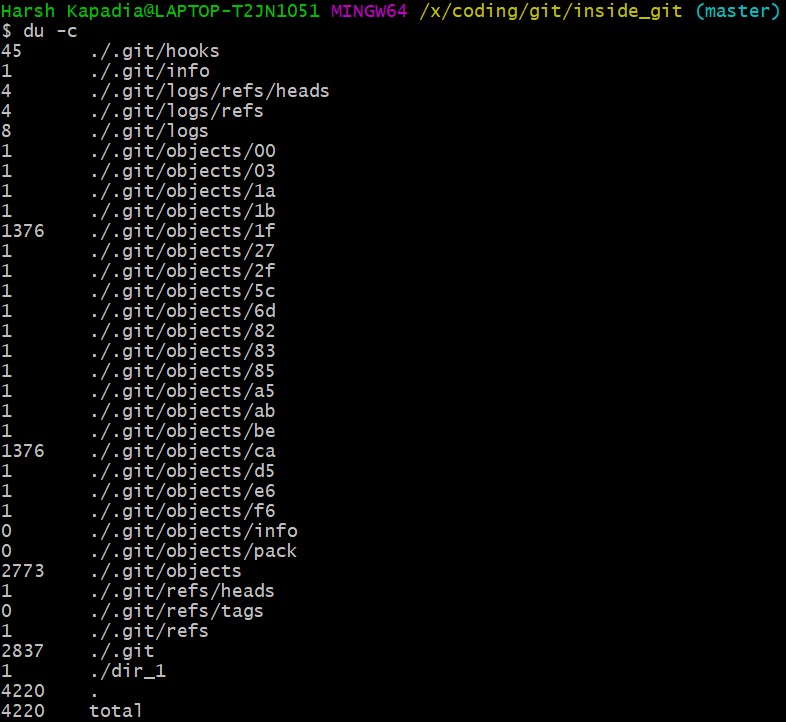
From the image above, there are two directories (.git/objects/1f and .git/objects/ca) with the same size (1376 kb).
NOTE: The directory content size (1376 kb) is greater than the image size (1374 kb) as Git adds the file type and size (length) to the blob file and then hashes it.
So is Git inefficient at handling huge files? No. The content of the file has changed and this produces a different SHA-1 hash (1f7af) than the original SHA-1 hash (ca893), so Git is not able to handle the change like it did when a file was simply renamed. Having multiple copies of such a huge file is not a problem in the local repository, but it will take up a lot of bandwidth while pushing and pulling from a platform like GitHub. To avoid this, Git uses Delta Compression. It stores the difference (diff) of the older file from the new one and indicates the new one as the parent. This is looked into in the sub-section below.
The pack Directory
.git
├───...
└───objects
├───...
└───pack
├───<*.idx>
└───<*.pack>
Delta compression is carried out when code is pushed/pulled to/from GitHub or when aggressive garbage collection (git gc --aggressive) is carried out.
Delta compression creates two files in .git/objects/pack
- A pack file (.pack)
- An index file (.idx)
The current state of the repo
The size of .git/objects/pack in the above image is 0 kb.
Aggressive garbage collection will be used to carry out Delta Compression and then du -c to view the changes.
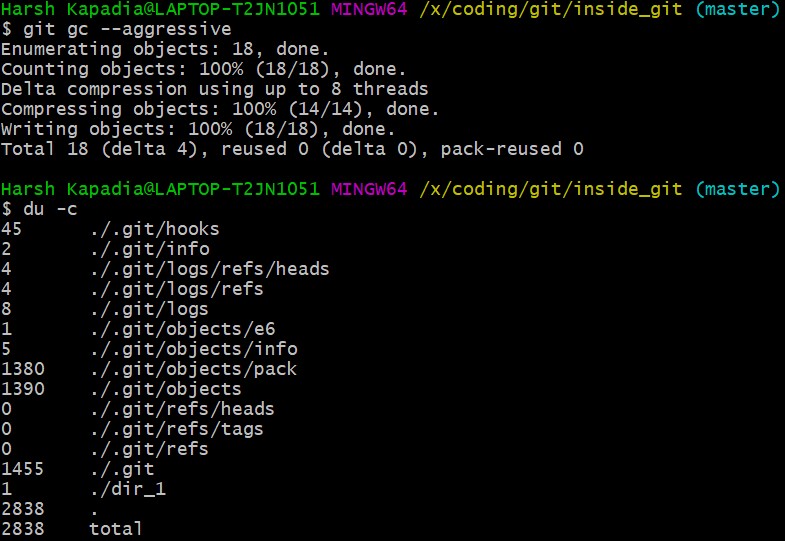
NOTE: The total size of the .git directory went down from 4220kb (seen in the first du -c image in this sub-section) to 2838kb (as seen in the above image). This is a 32.75% reduction in the size of the local repository!
Notice in the above image that the size of .git/objects/pack is 1380 kb and a lot of the files in .git/objects have disappeared, except for .git/objects/e6.
The contents of .git/objects/pack

As mentioned above, two files (a pack file .pack and an index file .idx) are created.
Check the contents of both the files using the plumbing command git verify-pack -v path/to/pack/file/<file_name>.pack (-v = verbose). (Works with the .idx file as well.)
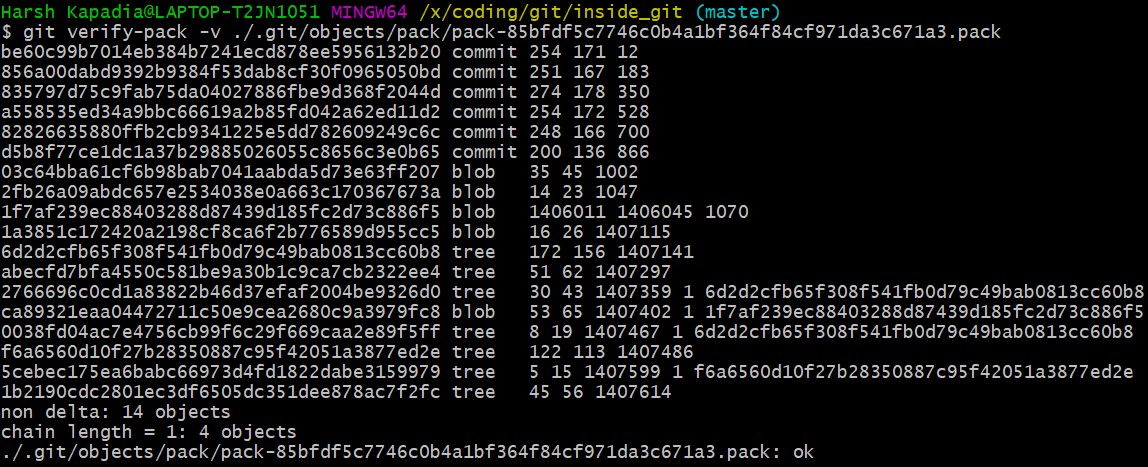
The pack file is a single file containing the contents of all the objects that were removed from the file system.
The size of the newly modified image (hash 1f7af) is very large. The blob of the original image (hash ca893) is very small in size in comparison and it has the hash of the modified image (1f7af) mentioned after it, indicating that its parent is the newly modified file. Thus, Git stored the entire new file and only a diff for the older file with a pointer to the newer file rather than storing the entire file twice, making it space efficient.
The pack file has a graph in it, just like the commit, tree and blob files have one.
NOTE: The .idx (index) file stores the same content as the .pack file and is a file that contains offsets into the pack file so you can quickly seek to a specific object.
On running the aggressive garbage collection, Git got rid of all the files in .git/objects that were connected with commits and added them to the pack file.
The .git/objects/e6 directory did not get removed as it was not related (connected) to any Tree Object.
An example similar to the one discussed in this sub-section.
Finally, take a look at the log of the repository.